The Road To Serverless: Multi-tenancy
Last modification on
Author: Ed Huang (i@huangdx.net), CTO@PingCAP
The Road to Serverless:
Imagine if you need to support a large-scale database service with thousands of tenants in a cluster. Each tenant only accesses their own data, and there is a clear distinction between hot and cold data. As mentioned earlier, there may be 90% small-scale users, but you cannot predict when these users will suddenly grow. You need to design a system to handle this situation.
The most primitive method is to allocate a batch of machines to one user and another batch to another user. This physical isolation method is straightforward, but its drawbacks are inflexible resource allocation and many shared costs. For example, each tenant needs their own control system and log storage, which obviously makes it the most cumbersome physical isolation method.
The second way is to deploy on a container platform, utilizing virtualization to make the most of the underlying cloud platform’s resources. This method may be slightly better than the first solution, as it allows for more efficient utilization of the underlying hardware resources. However, the issue of shared costs mentioned earlier still exists.
The core idea behind the above two solutions is isolation. However, if you want to achieve a lower cost per user as the number of users increases, simply emphasizing isolation is not enough; Sharing is also required to achieve the desired effect of isolation.
TiDB Serverless allows multiple tenants to share a physical cluster while being logically isolated from each other from the perspective of different tenants. This is the key to reducing unit costs because multiple users share the same resource pool.
Sharing-based approach normally has some problems, such as insufficient resource sharing to meet the needs of large tenants, potential data confusion between tenants, and the inability to customize individual tenant requirements. Additionally, if a tenant requires customized functionality, the entire system needs to be modified to accommodate their needs, which can lead to decreased maintainability. Therefore, a more flexible and customizable multi-tenant implementation is needed to meet the diverse needs of different tenants. Let’s see how these issues are addressed in TiDB Serverless. Before introducing the design solution, let’s first look at some important design goals:
- Different tenants should not affect each other’s SLAs, and the data of different users should not be visible to each other.
- Different tenants should be able to flexibly share/isolate hardware resources.
- The blast radius should be minimized in the event of system failures.
To address the first point of isolating and making the data of different tenants invisible to each other, this question needs to be considered from two aspects:
physical storage and metadata storage.
Isolating physical storage is relatively easy. As mentioned in previous post, TiKV internally shards the data, so even if the data is stored in S3, we can effectively differentiate between data from different tenants key prefixs. In TiDB 5.0, a mechanism called Placement Rules has been introduced to provide users with an operational interface for controlling the physical distribution of data at the semantic level (https://docs.pingcap.com/tidb/stable/placement-rules-in-sql). In the initial design of TiDB, the storage layer was kept minimal in terms of key encoding for performance reasons, without introducing the concept of namespaces or additional prefix encoding for user data, such as adding tenant IDs to differentiate between data from different users. These tasks now need to be done, and they are not particularly difficult in the storage layer. More considerations need to be given to compatibility and migration plans.
In traditional distributed databases, metadata storage is part of the system. For example, in traditional TiDB, the primary part of metadata stored by the PD component is the mapping between TiKV’s Key-Value pairs and specific storage nodes. However, in a DBaaS (Database-as-a-Service) environment, metadata goes beyond that. A better design is to extract metadata storage as a separate, shared service for multiple clusters. Here are the reasons:
Metadata should be multi-level. In addition to the lower-level Key-Value mappings and storage node relationships, there are also relationships between DB/Table metadata and Key-Value pairs, tenant information and DB/Table relationships, tenant and cluster deployment relationships, etc. This information is valuable for scheduling. Looking back at the reflections on the early design of TiDB, one important lesson learned is that metadata should have more logical layers rather than just simple mappings of KV ranges (which was done well in the design of Spanner).
Metadata services should be scalable. When metadata becomes a service, it means it may need to support information from thousands of clusters. This implies that the volume of metadata can be significant. If we look at Google Colossus, its metadata is actually stored in a Bigtable (https://cloud.google.com/blog/products/storage-data-transfer/a-peek-behind-colossus-googles-file-system), which gives an idea of the scale.
Metadata will be relied upon by various services outside the database kernel. The most typical examples are billing and federated query services or data sharing scenarios.
Regarding the invisibility between tenants, there is another important module mentioned above, which is the Gateway we mentioned above. Without this, sharing an underlying TiDB cluster would not be feasible. This is easily understandable, similar to how you cannot have multiple root accounts in a database. Since TiDB uses the MySQL protocol, to achieve multi-tenancy, you always need to identify the tenant’s name somewhere. We chose a workaround: since we need to identify tenant information, it should be done at the beginning of a session. We only need to pass the tenant ID during authentication, and once the session is established, we naturally know which tenant the connection belongs to. As for compatibility with the standard MySQL protocol, session variables are not used. Instead, we simply add a prefix to the username. That’s why you see some strange prefixes before the usernames in TiDB Serverless.
Once the tenant ID is known at the beginning of the connection, all logical isolation can be achieved through this ID. As a proxy, the Gateway does more than a regular proxy. In TiDB Serverless, we directly extracted the code of the Session management module from the original TiDB codebase to implement the Gateway.
This design brings several benefits:
Tenant differentiation and awareness of connection sources (geographical regions).
Better traffic awareness/control
It is better to handle flow control at higher levels. When the storage layer already experiences significant pressure, there is usually limited space for flow control. Since the Gateway is the entry and exit point for all traffic, and TiDB Serverless, like AWS Dynamo, introduces the concept of Request Units (RU), controlling RU here is the most accurate.
Seamless upgrades and scaling
Similar to the second point, when the Gateway detects sudden traffic bursts or prolonged periods without traffic, it can easily inform the underlying tidb-server (SQL processing) resource pool to increase or decrease computing nodes or request different specifications of computing nodes for different types of requests. This is also key to supporting Scale-to-Zero.
Billing
Combining the second and third points with the automatic hot/cold separation design in the storage layer, the traffic information specific to each tenant on the Gateway is accurate, the underlying computing resources can be dynamically adjusted based on actual traffic, and cold storage (S3) is usually cost-effective. These factors allow us to implement a Pay-as-you-go payment model. Even though the Gateway itself is persistent, the associated costs can be distributed among a massive number of users.
Seamless upgrades for users
In traditional solutions, if the underlying database needs an update, it inevitably interrupts user connections, which is unfriendly to applications that rely on long-lived database connections (many developers often overlook the need for reconnecting 🤷). However, the Gateway module is lightweight and rarely requires upgrades. Therefore, we can maintain user connections at this level, allowing seamless updates at the underlying level. Users will observe slightly higher latency for a few requests, followed by a return to normal operation.
Extremely fast new cluster startup time
Creating a new cluster only requires adding some metadata and fetching a pod from the tidb-server resource pool. In our case, it’s about 20sec :)
The Gateway is stateless and persistent. Considering the added latency and benefits, we believe it is acceptable.
By modifying the Gateway and metadata, we achieved logical isolation of multiple tenants on a single physical cluster. But how do we avoid the “Noisy Neighbor” problem? As mentioned earlier, we introduced the concept of RU (Request Unit). This leads us to mention the Resource Control framework introduced in TiDB 7.0 (https://docs.pingcap.com/tidb/dev/tidb-resource-control). Similar to Dynamo, TiDB’s Resource Control also uses the Token Bucket algorithm (https://en.wikipedia.org/wiki/Token_bucket). It associates different types of physical resources with RU and applies global resource control using the Token Bucket mechanism:
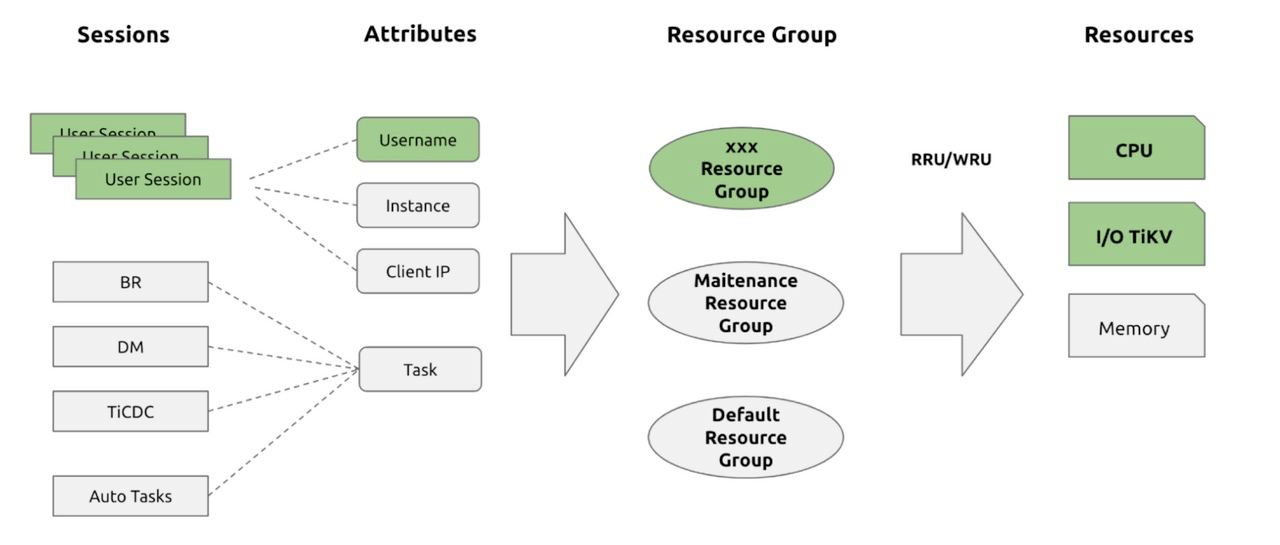
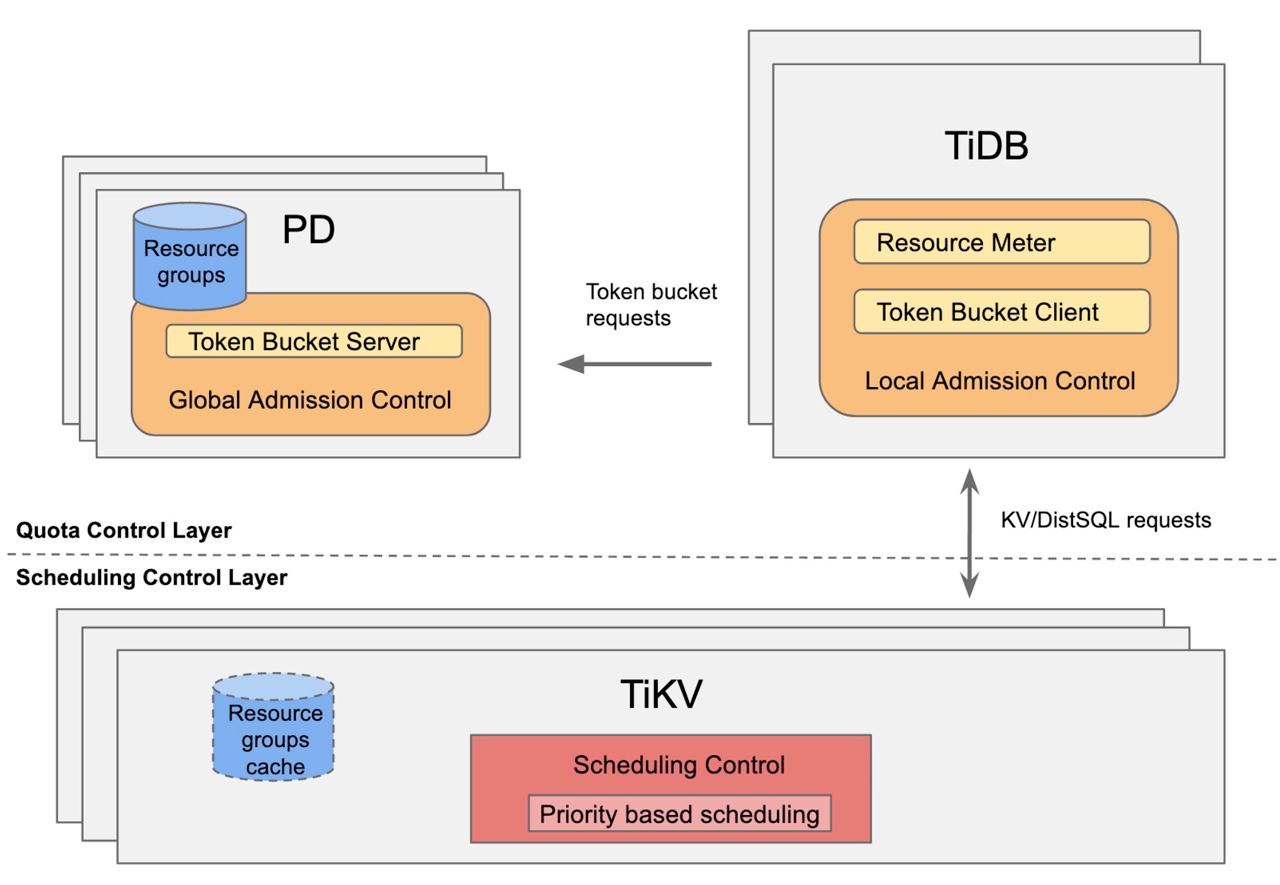
The benefits of implementing resource isolation through this approach compared to rigid physical isolation are evident:
Flexibility: This mechanism does not intrude upon the user’s access layer, making it orthogonal to TiDB’s original Data Placement mechanism. If a large customer requires a completely isolated environment, their data can be moved to a separate set of hardware resources with the help of Placement Rules, achieving hard isolation. The reverse is also easily achievable.
Support for burst and preemptive resource sharing: In situations where total resources are limited, burst and preemptive resource sharing are important strategies to handle sudden traffic spikes in critical business operations. This involves temporarily borrowing low-priority resources (or reserved resources) for high-priority applications. This is crucial for reducing overall costs while providing a good user experience for paying customers.
Resource reservation for predictable performance: Similar to the previous point, but with a subtle difference. In Dynamo’s new paper in 2022, they mention that for DBaaS, the concept of providing predictable performance is crucial, and I fully agree. I believe the key to predictability lies in avoiding hardware resource overload as much as possible. The most effective way to achieve this is by reserving resources in advance, and since all resources are precisely controlled by the Resource Control framework, reserving resources is easily achievable. There are actually more benefits mentioned in Dynamo’s paper, and they align with our practical experience.
However, implementing a multi-tenant service based on a shared large cluster poses a challenge: controlling the blast radius. For example, if a service experiences a failure or a severe bug, the impact may extend beyond a single tenant to a broader range. Currently, our solution is simple sharding, where a failure in one region does not affect another region. Additionally, for large tenants, we also provide traditional dedicated cluster services, which can be considered as an application-level solution to address this problem. Of course, we are continuously exploring this aspect.